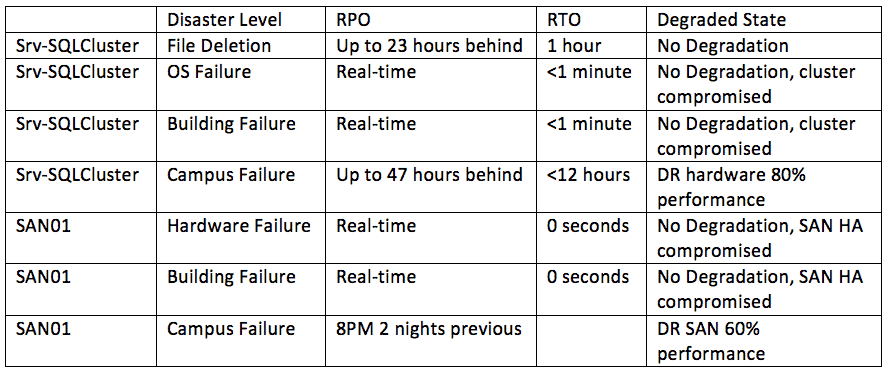
 The first thing that should be done before any server recovery is planned is to figure out four things for every workload: disaster classification, Recovery Point Objective (RPO), Recovery Time Objective (RTO), and Degraded State.
The first thing that should be done before any server recovery is planned is to figure out four things for every workload: disaster classification, Recovery Point Objective (RPO), Recovery Time Objective (RTO), and Degraded State.
Disaster Classification
Each business should establish its own disaster classifications, be that the disasters listed in the previous part of this series, or be that a subset of them or completely different ones. The business must designate a series of disasters that they are planning for.
Recovery Point Objective
This is the point in time that you want to be able to bring the server back to. If you backup once a day and that’s your only recovery method, your RPO would be your backup window for the previous night… but what if that backup hasn’t yet made it offsite? Now your recovery may be the previous week’s backup if the entire building burns.
Recovery Time Objective
This is the speed from which you recover from a disaster, regardless of the RPO. For example, if my backup is from two minutes ago, or two weeks ago, I should be able to bring the server back up in two hours.
Degraded State
This is how functional the environment is after recovering from the disaster. If I bring the system back up on the same hardware, no degradation. If I bring it back on a back up, lesser powered DR server, I may be at 80 percent performance, which is often acceptable depending on the disaster.
So what does this look like? Let’s use our previous example of an ESX host melting.
My Disaster Level might be “Single ESX host”, my RPO will be real time, and my RTO will be less than five minutes, my Degraded State might be “No tolerance for another host failure, performance 100 percent”. That’s assuming I have HA properly configured and my environment is fast enough to boot virtual machines that quickly.
Don’t miss the rest of our posts on disaster recovery:
Don’t let a disaster catch you off guard. Get set up with the right backup and disaster recovery solution today. Email us or give us a call at 502-240-0404 to get started with your DR planning.